MCGEE TECHNOLOGY
Data - Technology - Leadership
Prepare To Be Bombarded

We are all about to be bombarded with so much information we will not be able to keep on top of it. Some of us will be paralysed with indecision - Too much data will be a curse.
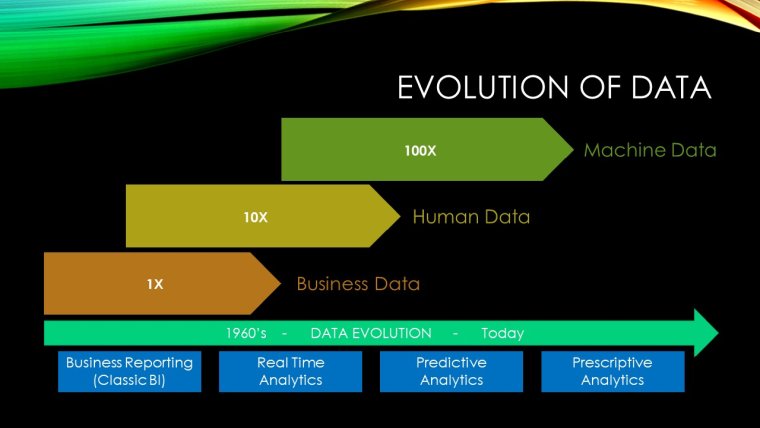
In storage circles we have been talking about machine generated data for several years now. If you are not familiar with the Evolution of Data story it goes like this.
Back in the early days of Electronic Data Processing the vast majority of data was business data, entered manually by data processing people and locked up in very structured databases, datasets and file systems.
Throughout the 60’s as mainframe systems such as IBM’s System/360 and 370 became commonplace in most businesses, these original Systems of Record started off the global data holdings by digitising older, paper based, business filing systems. We had records and fields and saw the rise of relational databases as a way to record and recall structured data.
Then with the advent of personal computers and their adoption into business in the 80’s and 90’s we saw a second, larger explosion of data that was generated by humans. As word processing, spreadsheets, electronic mail and desktop publishing took hold, it turned out humans were really good at cranking out ‘data’.
Indeed it was a great time to be in the storage business and we referred to all this new human generated data as ‘Unstructured Data’. Unlike the business data and Systems of Record before it there was a lot of noise in this data, a lot of low value data being churned out, a lot of Dilbert cartoons being replicated back and forth across email systems. All these office files and multimedia, text, diagrams, digitised images and sound was a big mess but we still kept it all because, you know, lawyers.
Then we started to define a new type of data. It was always there in the background but it started rising up to create more and more of a headache for storage and systems admins.
Machine generated data was mostly limited to things like log files, machine telemetry or limited types of object metadata. But as IT systems grew larger and more complex, so did the troubleshooting of issues, until log analysis and log file retention became a big deal. So much so that companies like Splunk and Sumo Logic made a nice business out of collecting and analysing them.
We knew back in the 2010’s that Machine Data was going to eclipse the massive amount of Human Data we were constantly churning out. We thought bold predictions like 100x was a big deal even though they are still wild guesstimates. Humans are good, but machines are relentless at generating data.
The Square Kilometre Array will consist of thousands of dishes and possibly up to a million antennas. It’s estimated that it could generate up to 1 exabyte of data per day at its peak. To put that in perspective an Exabyte is a billion, billion bytes, or 1,000 Petabytes. The UC Berkeley School of Information once predicted that all the words ever spoken by humans could be stored in 5 Exabytes.
So yes, machines are relentless at generating data.
Right now, we are on the cusp of another wave in this evolution of data. It’s really a new subset of Machine Data rather than a new category altogether and it’s what I think of as Machine Data made to look like Human Data. Or Machine Human Data.
We thought humans were pretty good at creating noisy human data. Well the machines are about to show us that not only will they relentlessly generate machine data but they are about to put us to shame with the creation of human data as well.
With the advent of neural networks, machine learning and natural language processing, techniques such as the GPT2 language model developed by OpenAI, machines are getting very good at writing coherent, legible texts. Try this at Talk to Transformer and let the machine finish your sentence for you:
https://talktotransformer.com/
Did you know that already a lot of sports results news stories are written by AI, or what is also known as algorithmic journalism? Actually any stories that are based on stats, metrics or results can easily be generated by machines. News organisations such as AP and Reuters use automation technology to write thousands and thousands of game recaps, based on scores and stats, for major sporting leagues such as soccer, basketball and football all around the world.
One AI sports writing tool boasts “ We deliver a concise, readable summary faster than anyone else.” Literally minutes after a game ends a story can be generated and posted to a news site. The same applies for financial news, company earnings reports and weather forecasts.
While the first few attempts at AI written novels haven’t won any awards yet the field of story generation is rapidly improving. A quick internet search will get you numerous free story plot generators you can play with.
Google have shown us their crossover AI and art experience using algorithmic generated poetry at PoemPortraits. I’m still bewildered by mine thank you Google - but I guess that’s art for you.

You might have better luck.
https://artsexperiments.withgoogle.com/poemportraits
And there are now also plenty of examples of AI generated music such as IBM’s Watson Beat which they used to generate custom original beats for Red Bull Racing.
Websites such as Forbes haven’t completely done away with humans yet, they have augmented them with ‘bionic’ powers in the form of Bertie, an AI content publishing platform that gives journalists real time story ideas and suggestions on how to format, structure and write content and headlines.
Meanwhile China's Baidu have developed a video generating AI algorithm that can produce up to 1,000 news summary video's per day, each created from a single URL input on a particular topic.
So where is this going? How does this play out in the near term? It inevitably means we will see a big increase in the number of sources of content. When we are no longer dependent on talented humans - artists, journalists, producers - to create content for our consumption, content production will rapidly accelerate in speed and amount.
Imagine the proliferation of news organisations when the entry point to a start up is simply having some tweaked ‘off the shelf’ AI and a cloud platform to process and publish.
Like the deluge of human generated data that emerged when the barriers to publishing came crashing down thanks to the internet and world wide web, so too we will see machine generated human content bombard us with varying degrees of quality material.
The signal to noise ratio is not necessarily going to improve - we will just be inundated with more of both the good , the bad and the ugly. The top shelf AI will outperform the second class AI systems and we will see the excellent, alongside the not very excellent content, flooding our inboxes, news feeds and social media streams.
Of course there will also be the malicious actors to contend with. When machine generating human content AI’s are cheap and ubiquitous there will be no shortage of deep fakes and election swinging fake news conspiracies blasting us from every which way.
So what can a mere mortal do to shield us from this oncoming tidal wave of information? Well, when we need to fight back against the machines, we need to enlist the help of other machines. Like those Forbes authors and their machine augmented powers, we will augment our capabilities with digital assistants. AI’s that can filter the onslaught of information to levels we can handle and hopefully distil down to the greatest value pieces for our individual needs.

Already AI powered email triage systems such as SuperHuman (https://superhuman.com/) promise to give you machine powered augmentation for what has become an unwieldy beast for many humans to try and manage solo - the email inbox.
Full service, multi-tasking AI assistants are not far away and the progress being made with Alexa, Siri, Cortana and Google Assistant will see these currently limited assistants evolve into our personal data filters and intuitive decision making bots.
Like Ray Kurzweil’s Singularity, the onslaught of machine generated human content is inevitable and about to bombard us from every direction. Our only likely hope to enable us to be able to pick out the important information from this sea of noisy, dirty data will be to augment our own human capability with that of the machines.
If we can achieve that and come out the other side with our bionic powers working - we may just see a leap forward in the information and decision making power we have at hand today.